
Machine Learning
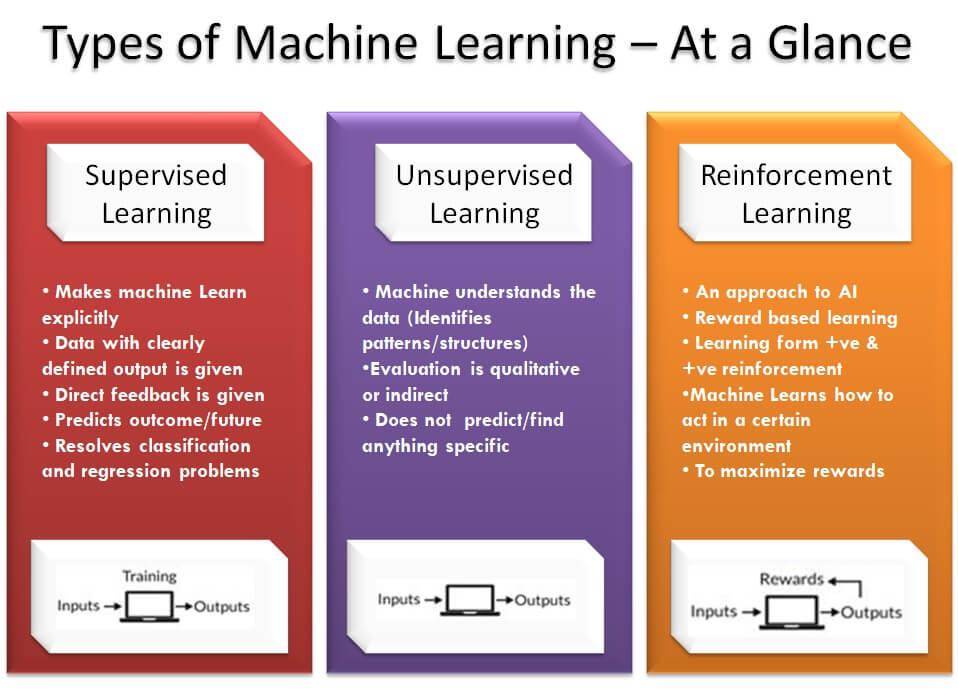
In machine learning, classification is a supervised learning method employed to categorize data sets base on classes, or labels provided to data.
See: “A Brief History of Facial Recognition”
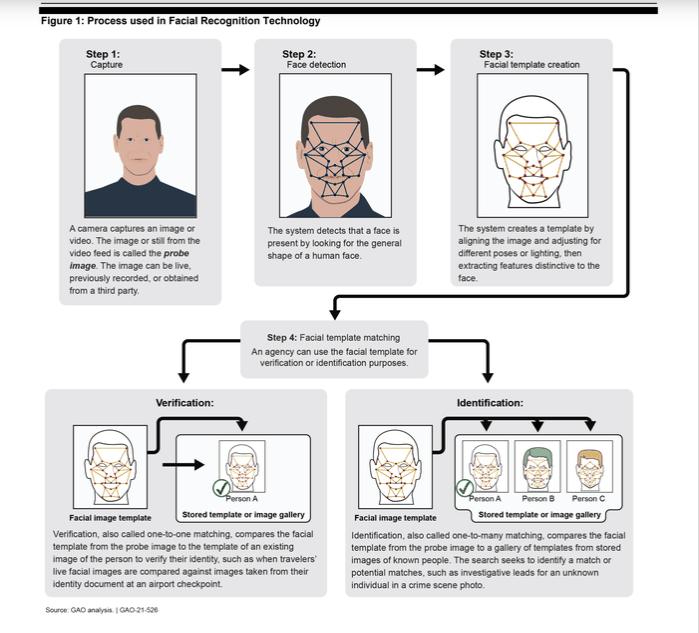
United States Government Accountability Office’s Report “Facial Recognition: Current and Planned Uses by Federal Agencies”, August 2021. According to the Verge, four agencies were found to use Clearview AI for face recognition.
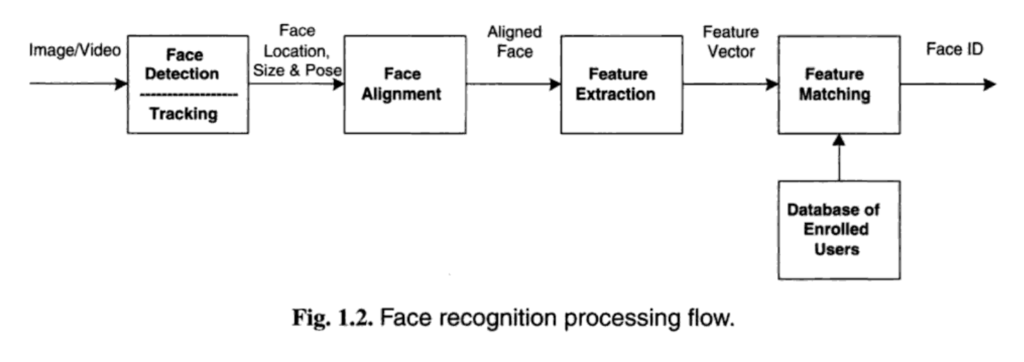
Most face recognition processes involve the following stages:
- Face Detection - actually using a machine learning model to identify the face. such a model would either be already trained on huge data sets of faces. After it’s detected the face is cropped such that all images are the same dimensions
- Face Alignment - correcting the positioning of the face so it is upright, not tilted like a questioning cat. Computers need consistency to analyze source material.
- Feature Extraction - Figuring out the location of eyes, nose, lips and mouth, or relationships between them. More to follow.
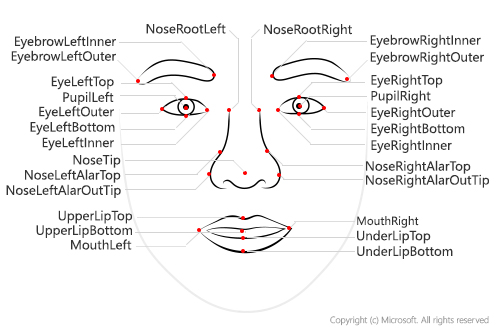
Face Landmarks (interchangeably “keypoints”) describe the positioning of common, standard facial features.
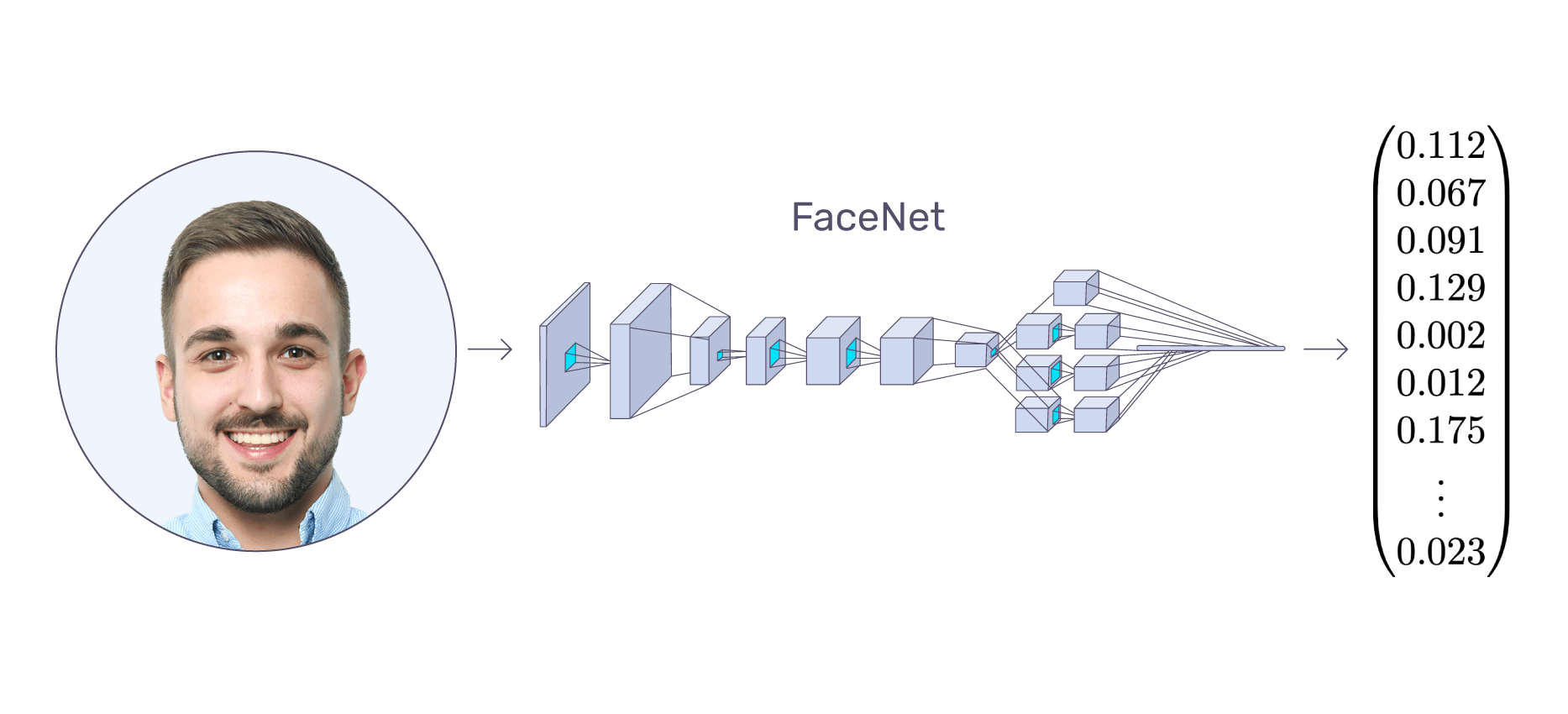
Face embeddings are vectors (a specific structure of numeric data) created as a result of machine learning process on a face image that creates a mapping from face images to a compact Euclidean space where distances directly represent face similarity.
- Feature Matching, Face Classification or Face Comparison for the purposes of verification or likeness assessment
Face recognition has been around since the 1940s. A face recognition model is a program (a series of files or even a single file) that has been trained to recognize one or multiple faces with algorithms that can be used alongside neural networks or computer vision libraries to detect and extract faces.
At the end of the day, data extracted from images is being compared or processed in different ways with the goal of finding a pattern or relationship, such as how similar one face is to another.
Ways of Detecting
There are many ways to detect faces–and efficiently too. We’ll go over a few primitive methods of face detection and extraction to test this.
TLDR; face detection requires differing calculations to figure out the key features of a face by using a series of algorithms to identify what’s considered important and unimportant to be face.
The following face detection methodologies are often taught and practiced by students in data science classes. There is nothing special about how the faces are extracted. Everything described is for demonstration only.
Haar Cascade Face Extraction
This method of face extraction arose through a proposal of object detection by Paul Viola and Michael Jones in their paper, "Rapid Object Detection using a Boosted Cascade of Simple Features" in 2001. This machine learning approach was initially developed for realtime face detection through the introduction of:
- an "integral image" to analyze images of any scale by reducing the calculation for any pixel to 4 pixels to speed up detection.
- a series of cascade functions to train classifiers with "positive images" [of faces] and "negative" images [non-faces].
- A learning algorithm called Adaboost that helped with identifying the most important features.
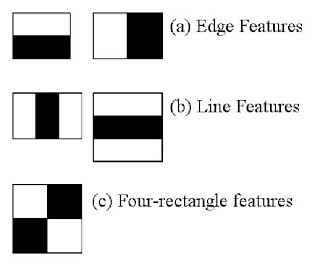
Each feature is a single value obtained by subtracting sum of pixels under the white rectangle from sum of pixels under the black rectangle.
This approach is most effective identifying frontal faces and isolated features like the eyes, nose and mouth.

Case in point: All the profile faces were left out.






Facenet
Despite using a convolutional neural network, Facenet still has capabilities to extract faces as part of its offerings. Currently, it’s considered one of the most accurate implementations of face detection available through open source.
Facenet introduces comparison of an anchor image (of the original face), and pairs of matching (positive) and non-matching (negative) images. More specifically, it uses a triple loss function to calculate distance between the anchor and positive images, and the distance between anchor and negative images.
By comparing the margin between positive and negative pairs, Facenet selects triplets of "Hard positives" and "Hard Negatives" for a mini batch of images (roughly 40 images per person), to predict whether whether a face matches any face within a collection of faces.

Members of the Einsatzgruppen 1939 and 1941, plot in Matplotlib

Female Concentration Camp Guards, plot in Matplotlib